2010年12月19日日曜日
ニューラルネットワーク、遺伝的アルゴリズムによる学習
トレードルールはシンプルであればあるほど良いと良く言われますが、私もきっとそのとおりだろうと思っています。RSIにしてもADXにしてもまた前回の記事で書いたボラティリティーのスクイーズや、しばらく前に書いたNaked Close等、それぞれ特有の相場の状況をより分かり易く表してくれていると思います。しかし実際にシステムにそれらを組み合わせて活かしきることは難しいなぁと感じています。
前々からニューラルネットワークとか遺伝アルゴリズムとかには興味があったのですが、今まではニューラルネットは複雑性を増してしまい「シンプル」からほど遠くなってしまいそうだったので手を出さずにいました。が今回はどうしてもニューラルネットワークを試してみたくなりました。というのも最近Webで情報集めをしていた時に見つけた海外の論文の中に、株価の予測(明日上がるか下がるか)を重回帰やARIMAなどの従来の手法で行う場合とニューラルネットワークを使う場合を比較研究したものがあり、興味をひかれたからです。それによるとニューラルネットワークの成績が他と比べてかなり良い感じで、その理由としてニューラルネットワークの非線形性をうたっていました。その論文を読んで即座に影響を受けてしまいとうとうニューラルネットワークを試すことにしました。手始めにニューラルネットワークについて書かれた情報をいろいろ集めました。取りあえず一番スタンダード(っぽい)一方向にだけ情報が流れる3層のニューラルネットワークを試すことにしました。
まずは指標の組み合わせにより、次の足で上がるか下がるかだけでもわかればと思って検証してみようと思いました。
今回は4年分16通貨ペア程度のデータで学習させて使っていない他のデータで検証するということを試みました。入力として与えてみたのは:
現在のRSI(9)、ひとつ前のRSI(9)、二つ前のRSI(9)、現在のCorrelation(24)、ひとつ前のCorrelation(24)、二つ前のCorrelation(24)の6つの値です。
※RSI(9)は期間=9のRSI、Correlation(24)は期間=24の終値とインクリメント値(現在が24、ひとつ前が23、その前が22というような一つずつ変わる数字)との相関値です。
ニューラルネットワークに学習させる方法として(これも標準的な方法なようですが)バックプロパゲーションなる方法をまず使って見ました。オーバーフィッティングを避ける方法として(これも海外のどこかの論文に書かれていて良く利用される方法なようです)学習用のデータとは別に検証用のデータでのパフォーマンスをウォッチしながら、検証用データでのパフォーマンスが伸びなくなったら学習をやめるという方法を用いました。
例えばEURUSD2004-2008を学習用データとしてニューラルネットワークに教え込んでいきます。教え込む際に現在のニューラルネットワークが答えとして返す値と実際の本当の値を比較して、その誤差が小さくなるように繰り返し処理を行います。学習用のデータであるEURUSD2004-2008では繰り返すほど誤差が小さくなっていくのですが、ある程度以上繰り返すとあとはいわゆるオーバーフィッティングになってしまうことになります。そこでEURUSD2004-2008とは別に例えばEURUSD2003を検証用に使うということを行います。(以下がそのイメージ)
学習用データの誤差(EURUSD2004-2008) 繰り返すごとに誤差が小さくなる
繰り返し1:100
繰り返し2:50
繰り返し3:30
繰り返し4:20
繰り返し5:17
繰り返し6:15
繰り返し7:14
検証用データの誤差(EURUSD2003) 繰り返しても誤差が小さくならない地点がある
繰り返し1:200
前々からニューラルネットワークとか遺伝アルゴリズムとかには興味があったのですが、今まではニューラルネットは複雑性を増してしまい「シンプル」からほど遠くなってしまいそうだったので手を出さずにいました。が今回はどうしてもニューラルネットワークを試してみたくなりました。というのも最近Webで情報集めをしていた時に見つけた海外の論文の中に、株価の予測(明日上がるか下がるか)を重回帰やARIMAなどの従来の手法で行う場合とニューラルネットワークを使う場合を比較研究したものがあり、興味をひかれたからです。それによるとニューラルネットワークの成績が他と比べてかなり良い感じで、その理由としてニューラルネットワークの非線形性をうたっていました。その論文を読んで即座に影響を受けてしまいとうとうニューラルネットワークを試すことにしました。手始めにニューラルネットワークについて書かれた情報をいろいろ集めました。取りあえず一番スタンダード(っぽい)一方向にだけ情報が流れる3層のニューラルネットワークを試すことにしました。
まずは指標の組み合わせにより、次の足で上がるか下がるかだけでもわかればと思って検証してみようと思いました。
今回は4年分16通貨ペア程度のデータで学習させて使っていない他のデータで検証するということを試みました。入力として与えてみたのは:
現在のRSI(9)、ひとつ前のRSI(9)、二つ前のRSI(9)、現在のCorrelation(24)、ひとつ前のCorrelation(24)、二つ前のCorrelation(24)の6つの値です。
※RSI(9)は期間=9のRSI、Correlation(24)は期間=24の終値とインクリメント値(現在が24、ひとつ前が23、その前が22というような一つずつ変わる数字)との相関値です。
ニューラルネットワークに学習させる方法として(これも標準的な方法なようですが)バックプロパゲーションなる方法をまず使って見ました。オーバーフィッティングを避ける方法として(これも海外のどこかの論文に書かれていて良く利用される方法なようです)学習用のデータとは別に検証用のデータでのパフォーマンスをウォッチしながら、検証用データでのパフォーマンスが伸びなくなったら学習をやめるという方法を用いました。
例えばEURUSD2004-2008を学習用データとしてニューラルネットワークに教え込んでいきます。教え込む際に現在のニューラルネットワークが答えとして返す値と実際の本当の値を比較して、その誤差が小さくなるように繰り返し処理を行います。学習用のデータであるEURUSD2004-2008では繰り返すほど誤差が小さくなっていくのですが、ある程度以上繰り返すとあとはいわゆるオーバーフィッティングになってしまうことになります。そこでEURUSD2004-2008とは別に例えばEURUSD2003を検証用に使うということを行います。(以下がそのイメージ)
学習用データの誤差(EURUSD2004-2008) 繰り返すごとに誤差が小さくなる
繰り返し1:100
繰り返し2:50
繰り返し3:30
繰り返し4:20
繰り返し5:17
繰り返し6:15
繰り返し7:14
検証用データの誤差(EURUSD2003) 繰り返しても誤差が小さくならない地点がある
繰り返し1:200
繰り返し2:110
繰り返し3:67
繰り返し4:50
繰り返し5:51 ★ここらへんで学習をやめる
繰り返し6:50
繰り返し7:52
この方法でバックプロパゲーションを用いて学習をさせて見ました。結果は少しだけ上手く行ったがいろいろ問題ありという感じでした。 学習にはある程度時間がかかることを覚悟していましたので数時間とかのレベルであれば良しとしようと当初から思っていました。また仮に1週間かかろうとよい学習をしてくれれば最終的には使えるはずと思っていました。
ところが実際にやってみると本当の問題は学習に時間をかけても必ずしも良い結果に行きつくとは限らないという点であることに気付きました。 Webでバックプロパゲーションについてもう少し詳しく調べるとバックプロパゲーションの弱点の一つに局所的な最適解にはまってしまう点があると書かれていました。 本当は日本海溝を探しだしたいのにそのあたりの溝に落ち込んでそこが一番深いところだと思い込んでいるような感じです。これを回避するための方法がいろいろ研究されているとのことでした。
そこで回避方法のなかで(プログラムを作る立場として)一番簡単そうな遺伝的アルゴリズムを利用してニューラルネットワークを学習させるという方法を試してみました。イメージとしてはバックプロパゲーションでニューラルネットワーク内のリンクの重みを決定するのではなく、遺伝的アルゴリズムで重みを決定するという感じです。
結果は以下の通りで個人的には「これならいけそうだ」と思えるものでした。今後につなげたいと思います。
データ:2003年~2006年(1時間足)
通貨ペア=15 "EURUSD", "GBPUSD", "USDCHF",
"USDJPY", "EURJPY", "GBPCHF",
"GBPJPY", "CHFJPY", "USDCAD",
"AUDUSD", "AUDJPY", "EURCAD",
"EURCHF", "EURGBP", "NZDJPY",
"NZDUSD"
※検証用は上記のうち 2003EURUSD, 2004GBPUSD, 2004CHFJPY, 2005EURJPY, 2005AUDJPY, 2006EURCADの6ペア/期間で残りを学習用データとして利用しました。
※検証用データにおいての勝率(上がるか下がるかがあたった確率)は52.68% (35,086本の足において) まだこれだと実戦には使えませんが、もう少し入力を工夫したりすればもっといけるのではないだろうかと感じています。(ちなみに学習用データでの勝率は53.08%でした。)
以下にニューラルネットワークを可視化してみた際の図を示します。(青が正の重み、赤が負の重みを表し、線の太さが重みの大きさを表しています。一番左の列が入力で上から(RSI現在、RSI一つ前、RSI二つ前、相関現在、相関ひとつ前、相関ふたつ前、そして一番下はバイアス(常に1)です)を表しています。真ん中の列は隠れ層、右側が出力です。)

今後やっていきたい事ですが:
※最終的には上がるか下がるかではなくて「今安全にエントリーできる場所かどうか」というような事を教え込みたいと思っています。
※データを年毎、カレンシーペア毎に分けて、あるいはもっと細かく分けてそれぞれのパフォーマンス(誤差二乗和で現在は測っている)だけでなく、それらのばらつきがより小さいものを探すようにさせたい。(ある年だけ上手く行くルールではなくてどんな年でも上手く行くようなものをより良いものとして判断するようにさせたい)
以下にニューラルネットワークを可視化してみた際の図を示します。(青が正の重み、赤が負の重みを表し、線の太さが重みの大きさを表しています。一番左の列が入力で上から(RSI現在、RSI一つ前、RSI二つ前、相関現在、相関ひとつ前、相関ふたつ前、そして一番下はバイアス(常に1)です)を表しています。真ん中の列は隠れ層、右側が出力です。)

今後やっていきたい事ですが:
※最終的には上がるか下がるかではなくて「今安全にエントリーできる場所かどうか」というような事を教え込みたいと思っています。
※データを年毎、カレンシーペア毎に分けて、あるいはもっと細かく分けてそれぞれのパフォーマンス(誤差二乗和で現在は測っている)だけでなく、それらのばらつきがより小さいものを探すようにさせたい。(ある年だけ上手く行くルールではなくてどんな年でも上手く行くようなものをより良いものとして判断するようにさせたい)
2010年12月13日月曜日
ボラティリティーの収縮(Volatility Squeeze)
ここ最近はボラティリティーのスクイーズ(収縮)を何とか利用できないものかと試行錯誤しています。いろいろなところでボラティリティーのスクイーズが発生した後にはボラティリティーの拡張が起こる等と書いてあります。例えば「ボリンジャーバンドの幅が狭くなったら値段が大きく動く前兆」というようなことやNR7などもこの現象をとらえようとするものだと思います。ボリンジャーバンド発案者であるボリンジャー氏の「ボリンジャー・バンド入門 」という本でも「低ボラティリティーは高ボラティリティーを呼び高ボラティリティーは低ボラティリティーを呼ぶ」というようなことが書かれています。自分で実際にチャートを眺めていても(例えば以下)これはその通りだと思えます。
」という本でも「低ボラティリティーは高ボラティリティーを呼び高ボラティリティーは低ボラティリティーを呼ぶ」というようなことが書かれています。自分で実際にチャートを眺めていても(例えば以下)これはその通りだと思えます。

いろいろやってみたのですが以下の2つのインディケータが今のところ一番上手い具合にとらえているのかなと思うものです。
(式1=下記の黄色い線) 式 : 100 × ATR(N) ÷ (過去N足の高値-安値)
大体30を超えたらエネルギーが溜まっている(収縮している)という感じで考えています。

(式2=下記の赤い線) 式 : 400 × ATR(N) ÷ 標準偏差(N)
45を超えたらエネルギーが溜まっていると考えます。400は4σ分ということで400としています。(特にそれ以外の根拠はありません) (黄色線は式1のもの)

両方とも一長一短という感じですが(2)の方が収縮をより早くとらえる感じです。

いろいろやってみたのですが以下の2つのインディケータが今のところ一番上手い具合にとらえているのかなと思うものです。
(式1=下記の黄色い線) 式 : 100 × ATR(N) ÷ (過去N足の高値-安値)
大体30を超えたらエネルギーが溜まっている(収縮している)という感じで考えています。

(式2=下記の赤い線) 式 : 400 × ATR(N) ÷ 標準偏差(N)
45を超えたらエネルギーが溜まっていると考えます。400は4σ分ということで400としています。(特にそれ以外の根拠はありません) (黄色線は式1のもの)

両方とも一長一短という感じですが(2)の方が収縮をより早くとらえる感じです。
これを実際にトレードシステムに組み込むにはどうすれば良いかという点は難しく今後の課題です。
2010年12月7日火曜日
為替相場はランダムウォーク (Random Walk)ではない!
いつもいろいろとWebで情報集めをしているのですが、しばらく前から「ランダムウォーク」というキーワードが気になっていろいろ調べています。というのも、もしも仮に相場がランダムウォークであれば、今自分がやっている検証が根本から意味がないという事になるからです。どうか「ランダムウォークでないでくれ」と思いながらいろいろ情報集めをしたのですが、いろいろ調べてみるとしっかりと研究している人たちが「ランダムウォークです」と結論付けたケースもあれば、「そうではありません」と結論付けた研究者もいるといった具合でした。
いろいろサイトを巡回しているとランダムウォークにより擬似的に作られたデータであっても、あたかもトレンドが発生したように見えたりして本物データと見分けが付きません。
そこでまずは自分でも「ランダムウォークデータを作ってみよう」と考えました。
現在私が検証しているデータは16通貨ペア、2001年から2010年の途中までの1時間足というものです。これらのファイルは全部で16x10年=160個(実際にはデータが無い年が若干あるので150個程度)で、各通貨ペア/年毎に別ファイルに保存して利用しています。
まずはこれらのそれぞれのファイル毎に足毎のリターン平均と標準偏差を求めました。例えば以下のような感じです。
EURUSD/2001 AVG= -0.000011, SD= 0.001283
GBPUSD/2001 AVG= -0.000008, SD= 0.001486
USDJPY/2001 AVG= 0.002737, SD= 0.156111
それに基づいて5秒に一回ランダムウォークをさせてみてデータを生成してみました。ランダムウォークは以下のように行いました。
現在のプライス = 5秒前のプライス + 正規乱数(@5秒枠に調整済みAVGとSD)
※5秒枠に調整済みAVG=上記で得られえたAVG÷(60分×12) (この調整の計算はこれでよいのかいまひとつ不安)
※5秒枠に調整済みSD=上記で得られたSD÷SQRT(60分×12)
各足(1時間)毎に始値から720回ランダムウォークを行い高値と安値を決定します。そして720回目のランダムウォークを終わった時点のプライスが終値ということになります。
以下はそのランダムウォークにより生成したデータの一例ですが、パッと見実際のデータと区別が付きません!

いろいろサイトを巡回しているとランダムウォークにより擬似的に作られたデータであっても、あたかもトレンドが発生したように見えたりして本物データと見分けが付きません。
そこでまずは自分でも「ランダムウォークデータを作ってみよう」と考えました。
現在私が検証しているデータは16通貨ペア、2001年から2010年の途中までの1時間足というものです。これらのファイルは全部で16x10年=160個(実際にはデータが無い年が若干あるので150個程度)で、各通貨ペア/年毎に別ファイルに保存して利用しています。
まずはこれらのそれぞれのファイル毎に足毎のリターン平均と標準偏差を求めました。例えば以下のような感じです。
EURUSD/2001 AVG= -0.000011, SD= 0.001283
GBPUSD/2001 AVG= -0.000008, SD= 0.001486
USDJPY/2001 AVG= 0.002737, SD= 0.156111
それに基づいて5秒に一回ランダムウォークをさせてみてデータを生成してみました。ランダムウォークは以下のように行いました。
現在のプライス = 5秒前のプライス + 正規乱数(@5秒枠に調整済みAVGとSD)
※5秒枠に調整済みAVG=上記で得られえたAVG÷(60分×12) (この調整の計算はこれでよいのかいまひとつ不安)
※5秒枠に調整済みSD=上記で得られたSD÷SQRT(60分×12)
各足(1時間)毎に始値から720回ランダムウォークを行い高値と安値を決定します。そして720回目のランダムウォークを終わった時点のプライスが終値ということになります。
以下はそのランダムウォークにより生成したデータの一例ですが、パッと見実際のデータと区別が付きません!

次に最近検証している回帰線の傾きでエントリーしてNCトレーリングでエグジットするという戦略でランダムウォークデータに対してこの戦略を適用した場合と、実際の2001年から2010年までのデータに対してこの戦略を適用した場合を比較してみました。
この戦略は期間Xの回帰線の傾きが下降から上昇に転じたらロングエントリーしてあとはファクターYのNCトレーリングを行ってストップに引っかかったらエグジットするというものです。(ショートはこの逆) 同時に最大一つのポジションを固定サイズでトレードし、エグジット後には次のトレードチャンスが来るまで待機します。 スプリットは0.025%(例えば1ドル100円ならば2.5pips分、1ポンド150円ならば3.75pips分ということになります)でシミュレートしました。
検証したパラメータは以下の通りです。
期間Xは20~30、刻み1
ファクターYは3.0~5.0を刻み0.25
合計でざっくりと 11期間 × 16通貨 × 10年 ×9ファクタ ≒15000とおりのパラメータ・データの組み合わせで行いました。以下がその結果で「ランダムウォークだと儲からないが本物の実データなら少し儲かる」という結果が出ました。(平均損益も上記のスプリットと同様に%ベースで計算しています)
実データの場合:
16通貨ペア全部、全パラメータ、全期間平均
1トレードあたりの平均損益:+0.028%、標準偏差=0.102%
プロフィットファクタ平均:1.10
ランダムウォークデータの場合:
16通貨ペア全部、全パラメータ、全期間平均
1トレードあたりの平均損益:-0.015%、標準偏差=0.126%
プロフィットファクタ平均:0.97
ランダムウォークデータの平均損益は理想的(?)にはスプリット分である-0.025%になるはずですがデータ数が足りないのかそこまでの精度はないようです。(今回のデータ数は上記のとおり15,000程度です。あと原因として考えられるのはプログラムのバグですが…) 以前今回の意図とは全く別の意図で検証したランダムシミュレーションにおいて、データ数=150,000程度(今回の10倍)に対して-0.025%の桁までがきっちりと計算できた事がありますので今回はサンプル数が少ないという事かなぁと思っています。
通貨ペア毎の結果は以下のような感じで、この結果を見る限りにおいて為替相場はランダムウォークではないと言えるのではないでしょうか。 (※この結果は今後も検証を続けて行こうと思えるもので個人的にはとてもうれしい結果です!)
実データの場合(通貨ペア毎、全パラメータ、全期間平均):※平均損益は1トレードあたりの損益平均
EURUSD:平均損益= 0.033%、 PF= 1.13
GBPUSD:平均損益= 0.024%、 PF= 1.10
USDCHF:平均損益= 0.024%、 PF= 1.12
USDJPY:平均損益= 0.030%、 PF= 1.13
EURJPY:平均損益= 0.051%、 PF= 1.18
GBPCHF:平均損益= -0.004%、 PF= 0.97
GBPJPY:平均損益= 0.055%、 PF= 1.19
CHFJPY:平均損益= 0.001%、 PF= 1.01
USDCAD:平均損益= 0.001%、 PF= 1.03
AUDUSD:平均損益= 0.054%、 PF= 1.16
AUDJPY:平均損益= 0.047%、 PF= 1.10
EURCAD:平均損益= -0.016%、 PF= 0.99
EURCHF:平均損益= 0.011%、 PF= 1.04
EURGBP:平均損益= 0.008%、 PF= 1.04
NZDJPY:平均損益= 0.100%、 PF= 1.25
NZDUSD:平均損益= 0.062%、 PF= 1.19
ランダムウォークデータの場合(通貨ペア毎、全パラメータ全期間平均):
EURUSD:平均損益= -0.027%、 PF= 0.96
GBPUSD:平均損益= -0.009%、 PF= 0.94
USDCHF:平均損益= -0.045%、 PF= 0.92
USDJPY:平均損益= -0.016%、 PF= 0.98
EURJPY:平均損益= -0.007%、 PF= 1.03
GBPCHF:平均損益= -0.046%、 PF= 0.87
GBPJPY:平均損益= 0.010%、 PF= 1.03
CHFJPY:平均損益= 0.038%、 PF= 1.12
USDCAD:平均損益= 0.038%、 PF= 1.12
AUDUSD:平均損益= 0.010%、 PF= 1.06
AUDJPY:平均損益= -0.031%、 PF= 0.99
EURCAD:平均損益= -0.033%、 PF= 0.93
EURCHF:平均損益= -0.026%、 PF= 0.87
EURGBP:平均損益= -0.045%、 PF= 0.83
NZDJPY:平均損益= -0.047%、 PF= 0.92
NZDUSD:平均損益= -0.006%、 PF= 1.00
2010年11月28日日曜日
レンジ判別フィルター
レンジとトレンドの判別をするフィルターはいろいろな方法があると思うのですがなかなか実際に組み合わせて使おうとすると上手くいかないなぁーと常々思っています。例えば長期の移動平均が示す方向だけにエントリーするというようなことが本に書かれていたりしますが、実際に組み合わせてみると今一つ上手く行きません。
この間の記事に書いたNC(Naked Close)トレーリングをいろいろ試していたときに、ふとNaked Closeがレンジ判別に使えるかもしれないと思ったので早速試してみました。
ちなみにNaked Closeとは現在の終値がひとつ前の足の高値を超えているかあるいはひとつ前の安値より下の場合を言います。Naked Closeが発生する状況とはどういう状況なのか考えてみると、(ロングの場合)少なくともひとつ前の高値を超えた状況(新値)で且つある程度の勢いがある状況と言えるかと思います。Naked Closeがよく発生するのはトレンドが発生した時と、後はトレンドが終わる前に急上昇するような場合のようです。
Naked Closeをフィルターにどう使うかということは前述のとおりNCトレーリングをもう少し改良できないかということを考えながらチャートを眺めていた時にひらめきました。チャートを眺めていると例えば上昇トレンドが発生した状態ではロング方向のNCトレーリングの値もショート方向のNCトレーリングの値も実値の下にある状態になります。一方でレンジの場合にはロング方向のトレーリングとショート方向のトレーリングの間に実値があるような状態となります。
これを利用してトレーリングラインのロング方向とショート方向の間に実値がある場合をレンジとし、どちらのトレーリングラインよりも上に実値がある場合を上昇トレンド状態、下にある場合を下降トレンド状態として表示させて見ました。以下の緑の線と赤の線がトレーリングラインで、この2本の線の両方の上に実値(今回は (High+Low+Close)÷3で計算しています)がある場合は上昇OK、両方の下に実値がある場合は下降OK,そうでない場合はレンジとしています。下の赤と緑がフィルター状況を表しています。赤が下降トレンド状態、緑が上昇トレンド、何もないところ(黒)はレンジを表しています。
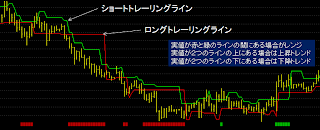
補足でもう一枚画像を載せておきます。水色でSMA(20)を表示しています。また一番下の赤と緑はSMA(20)の傾きがプラスかマイナスかを表しています。SMAではだましが発生するような横ばいの状況でそこそこ上手くフィルタリングができている感じです。

この間の記事に書いたNC(Naked Close)トレーリングをいろいろ試していたときに、ふとNaked Closeがレンジ判別に使えるかもしれないと思ったので早速試してみました。
ちなみにNaked Closeとは現在の終値がひとつ前の足の高値を超えているかあるいはひとつ前の安値より下の場合を言います。Naked Closeが発生する状況とはどういう状況なのか考えてみると、(ロングの場合)少なくともひとつ前の高値を超えた状況(新値)で且つある程度の勢いがある状況と言えるかと思います。Naked Closeがよく発生するのはトレンドが発生した時と、後はトレンドが終わる前に急上昇するような場合のようです。
Naked Closeをフィルターにどう使うかということは前述のとおりNCトレーリングをもう少し改良できないかということを考えながらチャートを眺めていた時にひらめきました。チャートを眺めていると例えば上昇トレンドが発生した状態ではロング方向のNCトレーリングの値もショート方向のNCトレーリングの値も実値の下にある状態になります。一方でレンジの場合にはロング方向のトレーリングとショート方向のトレーリングの間に実値があるような状態となります。
これを利用してトレーリングラインのロング方向とショート方向の間に実値がある場合をレンジとし、どちらのトレーリングラインよりも上に実値がある場合を上昇トレンド状態、下にある場合を下降トレンド状態として表示させて見ました。以下の緑の線と赤の線がトレーリングラインで、この2本の線の両方の上に実値(今回は (High+Low+Close)÷3で計算しています)がある場合は上昇OK、両方の下に実値がある場合は下降OK,そうでない場合はレンジとしています。下の赤と緑がフィルター状況を表しています。赤が下降トレンド状態、緑が上昇トレンド、何もないところ(黒)はレンジを表しています。

補足でもう一枚画像を載せておきます。水色でSMA(20)を表示しています。また一番下の赤と緑はSMA(20)の傾きがプラスかマイナスかを表しています。SMAではだましが発生するような横ばいの状況でそこそこ上手くフィルタリングができている感じです。

自分では「これは結構面白いフィルターかもしれない!」と思っているのですが、実際に上手く組み合わせて使えるかどうかを今後はもう少し検証したいと思っています。こういう検証をやっていると「自分の発見は大発見!」と思いたい発見(?)が多々ありますが、実際にしばらく検証すると全然使えない代物ということが良くありますねー。これもその一つかもしれません。
2010年11月25日木曜日
NCトレーリングExit+ボリンEntryを検証
ATRトレーリングよりも良いトレーリングで説明したNCトレーリングをエグジットに使って、エントリーをボリンジャーの2σタッチでその方向へエントリーするという方法で検証して見ました。前回はエントリーは(方向もタイミングも)ランダムにて検証しましたが今回はエントリーにもう少し意味を持たせて見ての検証です。 ボリンジャーの期間は20から34の範囲で、そしてNCトレーリングのFactor(どれだけはなれてトレーリングするか)は2.5から6.0の範囲で検証を行いました。
例によって16通貨ペア、1時間足、2001年から2010年の途中までのデータで検証を行いました。結果は以下の通りでした。
平均PF=1.06
ランダムにエントリーしてNCトレーリングでエグジットした場合の平均利益は0.001%だったので今回の方が少し意味のあるエントリーになっているようです。この小さな数値の変化にどれだけ意味があるのか?とも思いますが、最近は「実はこの小さな違いも結構意味があるのでは」と思うようになっています。
パラメータ(2つ)と平均利益の関係図は以下のような感じでした。
 これによればボリンジャーの期間は24から28の範囲でトレーリングのFactorは4.5から5.5のあたりが良いようです。これだけ範囲がきれいに出ているというのは良いことだと思うのですが、平均利益が0.02%とかだとまだまだ勝てないですね。これをどうすればもっと勝てるようにできるのかが課題です。
これによればボリンジャーの期間は24から28の範囲でトレーリングのFactorは4.5から5.5のあたりが良いようです。これだけ範囲がきれいに出ているというのは良いことだと思うのですが、平均利益が0.02%とかだとまだまだ勝てないですね。これをどうすればもっと勝てるようにできるのかが課題です。
ちなみにボリンジャー以外のエントリー方法(平均移動クロス、ストキャスティックを使ったエントリー、などなど)もいろいろ試しつつあります。エントリーは少しタイミングが違うだけでどれでも同じようなものというような意識を持っていましたが、実際にいろいろ試すと結構違います。特にこの違いは平均利益とかProfitFactorではほぼ同じような数値であっても、上記のようなパラメータの関係図には結構違いがはっきり現れるようです。(上記のように比較的きれいに最適パラメータの範囲が見えるものとそうでないものがある) 参考までに以下は平均移動を終値がまたいだらその方向へエントリーといつ方法で検証を行った場合の結果です。
以下はパラメータと利益の関係図です。

例によって16通貨ペア、1時間足、2001年から2010年の途中までのデータで検証を行いました。結果は以下の通りでした。
平均PF=1.06
平均利益=0.015%
利益の標準偏差=0.101%
ランダムにエントリーしてNCトレーリングでエグジットした場合の平均利益は0.001%だったので今回の方が少し意味のあるエントリーになっているようです。この小さな数値の変化にどれだけ意味があるのか?とも思いますが、最近は「実はこの小さな違いも結構意味があるのでは」と思うようになっています。
パラメータ(2つ)と平均利益の関係図は以下のような感じでした。

ちなみにボリンジャー以外のエントリー方法(平均移動クロス、ストキャスティックを使ったエントリー、などなど)もいろいろ試しつつあります。エントリーは少しタイミングが違うだけでどれでも同じようなものというような意識を持っていましたが、実際にいろいろ試すと結構違います。特にこの違いは平均利益とかProfitFactorではほぼ同じような数値であっても、上記のようなパラメータの関係図には結構違いがはっきり現れるようです。(上記のように比較的きれいに最適パラメータの範囲が見えるものとそうでないものがある) 参考までに以下は平均移動を終値がまたいだらその方向へエントリーといつ方法で検証を行った場合の結果です。
平均PF=1.04
平均利益=0.008%
利益の標準偏差=0.109%
以下はパラメータと利益の関係図です。

Pivot、R1,S1のヒット確率
本屋でしろふくろうさんという方の本を見かけ、その中に書かれていたPIVOTに到達する確率についての記述に興味をひかれました。しろふくろうさんはフィボナッチピボットを用いて5年分の日足データでPivot、R1,S1等のラインにどのくらいの確率で到達するのかを検証してみたとのことでした。それによればPivotラインにはかなりの確率(確か70%くらいだったと思います。記憶が定かではありません)でタッチするとのことで、その上下のR1、S1ラインにそれよりも少ない確率ですが何%かの確率で到達するというものです。興味深かったのは前日が上昇(前々日のClose<前日のClose)の場合にはR1への到達確率がS1への到達確率よりも大分大きいということ(前日が下降の場合はその反対)でした。
これは面白い!と思い早速自分でも検証してみました。私は現在1時間足のデータでいろいろ検証しているのでとりあえず1時間足で検証してみました。使ったのは例によって16通貨ペアで1時間足、2001年から2010年の途中までのデータです。Pivotの計算は以下のように行いました。(この計算はワイルダー氏の方法ではなくてフィボナッチピボットと呼ばれるものらしいです)
Pivot = (ひとつ前の足のH + ひとつ前の足のL + ひとつ前の足のC) ÷ 3
Range = ひとつ前の足H - ひとつ前の足L
R1=Pivot+Range*0.5
S1=Pivot-Range*0.5
ひとつ前の足の上下でR1とS1への到達確率が半々の確率でなくなるのであれば、あとは回数をこなせば勝てるということだと思って、そんなに簡単なことなのか?と思ってしまいました。(当然そんな簡単ではないということがいろいろやってみてわかりました。下記参照)
まずはPivotとR1、S1を計算して集計を行いました。結果は以下の通りで、確かに前日の上下によって到達確率にかなりの違いが見られます。例えばひとつ前が上昇の場合にはR1への到達確率がS1の到達確率と比較して結構違います。(下記のパーセントのカラムを足して100%にならないのは例えばR1とS1の両方に到達するケース等の重複があるからです)

おおよそ上下の方向によって53%対33%ということでこのままトレードの数をこなせば勝てるということだと早合点しました。
これはすごいと思って「いったい一回あたりのトレードでいくら勝っているのだろうか?」という点を次に調べようと思いました。上昇もしくは下降でCloseした足の次の足の始値でエントリーすると仮定して、始値からR1およびS1までの価格差(距離)を測ったところ以下のような集計結果が出ました。(下記は距離をパーセンテージベースの価格で表しています。)

これはつまり前日が上昇だった場合は(少し考えると当然なのですが...)始値からR1までの距離が始値からS1までの距離よりも短くなり、逆に前日が下降だった場合は始値からS1までの距離がR1までの距離よりも短くなるので、必然的に到達確率が良くなるということでした。距離と到達確率を掛け算してみるとほぼトントンという結果でした。
ということで今回は「そんな上手い話しがあるはずないか」という結論でした。
こう言ったぬかよろこびは検証をしていると良くありますね。 多くの場合はプログラムミスとかそんな結論なのですが今回も少し残念でした。
しかしこの確率を検証してみると言う考え方は今後活用したいと思いました。
これは面白い!と思い早速自分でも検証してみました。私は現在1時間足のデータでいろいろ検証しているのでとりあえず1時間足で検証してみました。使ったのは例によって16通貨ペアで1時間足、2001年から2010年の途中までのデータです。Pivotの計算は以下のように行いました。(この計算はワイルダー氏の方法ではなくてフィボナッチピボットと呼ばれるものらしいです)
Pivot = (ひとつ前の足のH + ひとつ前の足のL + ひとつ前の足のC) ÷ 3
Range = ひとつ前の足H - ひとつ前の足L
R1=Pivot+Range*0.5
S1=Pivot-Range*0.5
ひとつ前の足の上下でR1とS1への到達確率が半々の確率でなくなるのであれば、あとは回数をこなせば勝てるということだと思って、そんなに簡単なことなのか?と思ってしまいました。(当然そんな簡単ではないということがいろいろやってみてわかりました。下記参照)
まずはPivotとR1、S1を計算して集計を行いました。結果は以下の通りで、確かに前日の上下によって到達確率にかなりの違いが見られます。例えばひとつ前が上昇の場合にはR1への到達確率がS1の到達確率と比較して結構違います。(下記のパーセントのカラムを足して100%にならないのは例えばR1とS1の両方に到達するケース等の重複があるからです)

おおよそ上下の方向によって53%対33%ということでこのままトレードの数をこなせば勝てるということだと早合点しました。
これはすごいと思って「いったい一回あたりのトレードでいくら勝っているのだろうか?」という点を次に調べようと思いました。上昇もしくは下降でCloseした足の次の足の始値でエントリーすると仮定して、始値からR1およびS1までの価格差(距離)を測ったところ以下のような集計結果が出ました。(下記は距離をパーセンテージベースの価格で表しています。)

これはつまり前日が上昇だった場合は(少し考えると当然なのですが...)始値からR1までの距離が始値からS1までの距離よりも短くなり、逆に前日が下降だった場合は始値からS1までの距離がR1までの距離よりも短くなるので、必然的に到達確率が良くなるということでした。距離と到達確率を掛け算してみるとほぼトントンという結果でした。
ということで今回は「そんな上手い話しがあるはずないか」という結論でした。
こう言ったぬかよろこびは検証をしていると良くありますね。 多くの場合はプログラムミスとかそんな結論なのですが今回も少し残念でした。
しかしこの確率を検証してみると言う考え方は今後活用したいと思いました。
登録:
投稿 (Atom)